Table of Contents
Large Language Models (LLMs) have emerged as a leading force in the development of new AI capabilities, and everything from chatbots to content generators. As the world embraces more AI-driven solutions, the demand for more tailored LLM applications has recently exploded. This creates an opportunity for startups, enterprises, and anyone trying to build their own LLM platform. But how do you build one from scratch?
This blog examines how to build a large language model from scratch, encompassing all aspects, from data gathering to model architecture, training, tuning, and ultimately deployment. Whether you are a developer interested in AI models or a business that would like to develop a domain-specific LLM, this guide gives you the complete roadmap to turn your AI idea into a fully functional product.
What is an LLM? Understanding the Core Before You Build One
A Large Language Model (LLM) is the most advanced type of artificial intelligence system designed to understand, process, and generate human language text through massive data. LLMs apply deep learning methods such as transformers to fully comprehend language structure, context, and semantics.
This enables them to process even more complex language structures. Older models or AI did not use as much data and relied more heavily on pre-defined rules of language and less structured data. LLMs are trained based on processing billions of words and can create, predict, and summarize responses with appropriate context and ease of fluency. With his basic understanding, now we shall move into the core tools and resources for building an LLM.
Essential Tools and Resources to Build an LLM Effectively
The process of creating a Large Language Model involves a significant investment of resources and the combination of the right technologies, data, and skilled personnel. A thorough groundwork of tech is necessary for the LLM model before its actual build-up to guarantee scalability, precision, and energy-saving operation.
1. Technical and Hardware Considerations
LLMs require high computational power for training and inference. You will need GPUs (Graphics Processing Units) or TPUs (Tensor Processing Units) in addition to high-memory servers and sustained storage systems. Using cloud-based GPU clusters, such as those offered by AWS, Azure, Google, etc., can help with efficiency and costs when scaling up training efforts.
2. Data Preparation
Clean, diverse, domain-specific data are the foundation of your model. Focus on preparing your data for collection, cleaning, tokenization, and labeling to make the training confident in its accuracy. In addition to open datasets, you can also use your proprietary data to improve contextual accuracy.
3. Development Stack
Python-based languages, PyTorch, or TensorFlow frameworks, and Hugging Face Transformers libraries will be the main tools for the prototype modeling process and the iteration on it. The model’s integration and its performance tracking through adoption would require tools like Weights & Biases or MLflow, which would be useful.
4. Team Setup
A multi-disciplined team of data scientists, machine learning engineers, linguists, and DevOps is vital for a successful LLM project. They can collaboratively address every phase of model development, from deployment training.
So far, we have seen the basic elements to build an LLM. Now let’s dive into the next phase…
How to Build an LLM – A Step-by-Step Guide from Scratch?
Creating a Large Language Model (LLM) is a challenging but rewarding task. It involves combining data science, machine learning, and linguistics. To build a model that operates accurately, you should pay careful attention to each phase of the research endeavor, from goal definition to deployment. Below is an LLM construction plan tailored to your commercial needs.
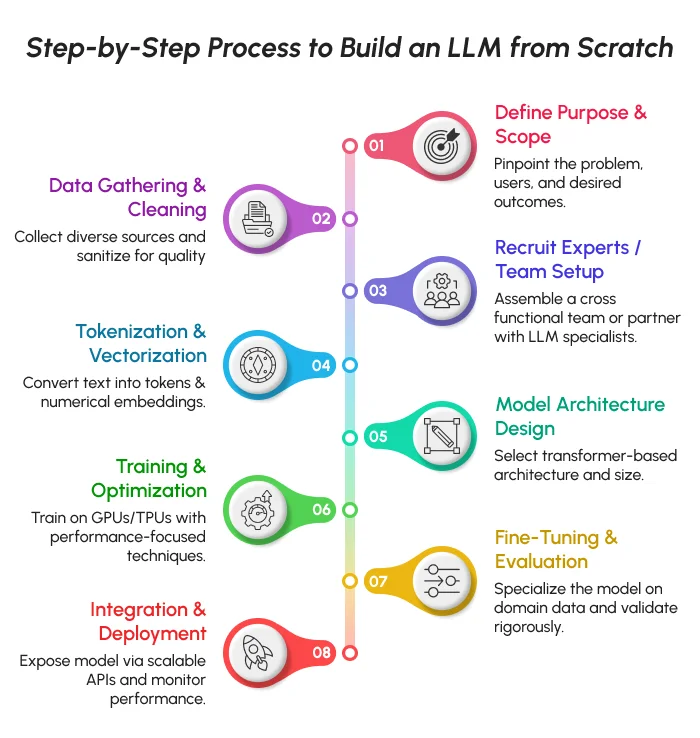
1. Define the Purpose and Scope
Define the problem your model is solving and your targeted users. For instance, your LLM may be designed for automating customer support, writing content, or summarizing information.
Clarifying the scope of the project will direct you to the right data type, computational resources, and output types. It also aids in controlling the complexity at a minimum level, thereby keeping your project in sync with verifiable business goals.
2. Data Collection and Preprocessing
An LLM’s effectiveness is reliant upon its training data. The first step in preparing your model should be to gather data sets from books, articles, websites, and open repositories on a large scale. The next step is to clean the data you have gathered through data cleaning, deduplication, and normalization, to eliminate errors and biases.
This process helps to train your LLM in a correct and precise manner with respect to syntax, grammar, and context. You should incorporate proprietary data sources as well as open-source ones. Employing both sources of data can contribute to the model’s diversity and increase its generalization capability.
3. Recruit Experts from an LLM Development Company
Creating an LLM is not a one-person job. It takes a coordinated team of AI developers, data scientists, NLP specialists, and cloud engineers. Hiring an established LLM development company gives you access to tried and tested frameworks, optimized pipelines, and best practices.
Experts can help you avoid common mistakes, which can streamline the model training process and deployment or functional AI solution faster and cost-effectively than other methods.
4. Tokenization and Vectorization
The model must understand the text in a machine-readable format before it learn from text. Tokenization refers to the breakdown of text into smaller, recognizable pieces generally termed words or characters. This breakdown enables pieces of text, referred to as tokens, to be expressed as numbers through a process called vectorization.
Once structured pieces of data are obtained, the language model can learn the meanings and relationships between the tokens during training.
Effective tokenization and embedding methods improve accuracy and reduce training time. It is understood that high quality in this step makes for better final output.
5. Model Architecture Design
The current LLMs, such as GPT, LLaMA, and Mistral, are based on the foundation of Transformer architecture. It uses an attention mechanism to understand word relationships, irrespective of the relative positioning of the words within the sentence.
During model architecture design, you will need to select the specific number of layers, attention heads, and parameters. At this point, performance optimization techniques such as dropout, residual connections, and layer normalization are also implemented to optimize stability and scalability.
6. Training and Optimization
Training is the phase where your LLM is trained on key language tasks like understanding and generating language. During training, you will be optimizing not only the model’s ability to learn, but also need to monitor metrics of the learning process, such as loss rate, accuracy, and perplexity.
You will be able to include further performance improvement strategies, such as mixed precision training, gradient clipping, and adaptive learning rates, to boost an otherwise efficient training process, or simply to reduce resource cost.
7. Model Fine-Tuning and Evaluation
Once you have created the base model, fine-tuning makes it smarter and more specific. While finetuning, introduce domain-specific datasets. Your model will learn how to adapt specific domains or topics such as finance, healthcare, education, etc.
Evaluation is an equally important aspect of your LLM. Use benchmark datasets and human reviewers to measure the model’s accuracy, recall, and contextual relevance. Continuous feedback and re-training cycles will help ensure your LLM remains accurate, domain-relevant, and free from bias.
8. Model Integration and Deployment
In the last phase, your trained model will be integrated further into real-world systems and application contexts. You can also work with scalable APIs and cloud spaces for efficient deployment. When deploying the LLM, latency, uptime, and optimization costs are factors to consider. Conducting real-world tests of your model can surface issues with the model itself, as well as discoveries about its performance in larger applications.
Building an LLM from scratch is a challenging but ultimately transformative process within the boundaries of data intelligence and computational power. Having grasped the method of constructing an LLM efficiently, the next step would be to improve its character, security, and scalability. Let us take a look at the significant characteristics you should incorporate for a more intelligent and production-ready custom LLM application.
Key Features to Integrate While Developing Your Custom LLM Application
Creating a custom large language model is not just about training; it also involves the integration of essential features that ensure a scalable, secure, and user-centric model. Below, we’ll see the right set of features to integrate into the LLM model.
1. Contextual Understanding
Enable LLM to interpret user intent and keep the conversation going by analyzing the text, which goes beyond just the words.
2. Multilingual Capability
The model is made to communicate in various languages without any trouble, which in turn makes it usable among international audiences.
3. Prompt Optimization Engine
The response quality is increased to a great extent by refining and adjusting prompts in a more flexible manner for more accurate and relevant outputs.
4. Knowledge Base Integration
This integration connects your model with the internal or external databases in order to supply accurate facts and real-time information.
5. Fine-Tuning Interface
This is the way that developers or admins have control over the model and can train it on certain datasets to boost the domain expertise or tone alignment.
6. Session Memory & Personalization
The LLM can remember prior conversations, which means that it can create individual and constant user experiences.
7. Content Moderation Layer
This layer ensures that no inappropriate or biased content makes it through, thereby allowing for safety, compliance, and consistency with the brand in all responses.
8. Monitoring Dashboard
Real-time analytics on the performance, accuracy, and user engagement are provided, which in turn allows the teams to optimize the model effectively.
9. Data Security Framework
Uses encryption, access controls, and compliance standards (such as GDPR) to protect user and training data.
10. API Scalability Support
Guarantees that your LLM can manage several requests at the same time and can be relied on even when there is a lot of traffic.
11. Performance Optimization & Caching
Lowers the delay and increases the speed of response by means of load balancing that is carried out efficiently and by the use of intelligent caching mechanisms.
12. Custom UI/UX Components
A smooth user experience is essential for effective LLM interaction. Partnering with expert UI & UX Designers ensures intuitive, responsive interfaces that make every interaction seamless.
The addition of these vital elements turns your LLM application from just a standard language model into a fully functional AI system ready for production. Every feature contributes to the system’s flexibility, accuracy, and lifetime scalability. After that, we will discuss the most frequent problems in LLM development and the effective solutions that will lead to a smooth and high-ROI result.
Common Challenges in LLM Development and How to Overcome Them
Building a Large Language Model (LLM) from scratch is a daunting task since these models raise numerous technical, ethical, and financial considerations. Regardless, it is important to address all of these considerations and think of actionable steps to mitigate them.
1. High Computing Costs
Training of LLMs is one of the more expensive aspects, as it requires full, large-configuration hardware and GPU power. Options for reducing the cost of high-scale training include cloud-based GPU clusters, auto-scaling infrastructure, and optimized training algorithms that are structured for cost rather than performance.
2. Data Bias & Ethical Risks
One factor that leads to biased outputs and misinformation is the use of unfiltered or unbalanced datasets. Try your best to avoid this by not only using diverse and balanced datasets, but also by practicing ethical AI with techniques such as fairness checks and human-in-the-loop validation.
3. Long Training Cycles
The training of large-scale models uses a lot of time and resources. Speed it up via distributed learning, parallel processing, and pipeline automation, which will all ultimately lead to greater efficiency and scalability.
4. Model Interpretability
The complexity of model architectures is often inversely proportional to the ease with which their decision-making process is understood. Provide model transparency by integrating explainable frameworks and visualization dashboards, thus fostering user trust in the technology.
However, the development of LLM is a resource-consuming endeavor, but the right technology stack and expertise can take care of these challenges in an effective manner. Early understanding of these barriers will lead to better planning and optimization of your resources for long-term success. Let us next examine the critical factor that every enterprise is curious about…
How Much Does It Cost to Build an LLM from Scratch?
Predicting the exact cost of building an LLM from scratch is a tedious task. The cost may vary based on factors such as model complexity, infrastructure, and team expertise. An advanced model may consume more resources and time. And also the cost may depend on the type of framework, and the scale of post-training operations like fine-tuning and testing.
If you are seeking to find out the exact cost of developing an LLM from scratch, you can contact Pixel Web Solutions’ team of experts. We will provide a comprehensive cost estimate specifically designed to suit your objectives, project specification, and technical requirements.
Why Choose Pixel Web Solutions for Your LLM Development?
Pixel Web Solutions is the upcoming Large Language Model Development Company in the industry. Our team of experts is passionate about creating LLM solutions that are robust, reliable, scalable, and efficient. We can help companies automate their tasks, streamline their decision-making processes, and improve customer service. We blend ingenuity and technical expertise to provide LLM models that can truly comprehend your data. Whether you need a chatbot, content generator, or an AI assistant for your company, we build LLM solutions that fit seamlessly within your objectives.
- Proficient AI and ML engineers with industry’s hands-on experience
- Personalized LLMs in line with your business objectives
- The entire process supports data preparation to implementation
- Effective Development within your budget
- Apply the newest AI frameworks and cloud infrastructure
- Rigorous privacy and data protection policies
